Hrvatski AI startup airt, čiji su osnivači Hajdi Ćenan i Davor Runje, u svibnju ove godine predao je prijavu za patent i globalnu zaštitu za neuronske mreže koje u sebi sadrže sloj objašnjivosti (explainability). Sada je stigla obavijest da im je taj patent i odobren, što je velika vijest za mali hrvatski startup koji je tim svojim inovativnim tehnikama bolji od sličnih sustava koji su trenutna industrijska praksa, a među kojima su i Googleove duboke lattice mreže.
Itekako zadovoljni što je airtu odobren patent, Hajdi Ćenan i Davor Runje pojasnili su neke odlike ovog inovativnog rješenja i svoje ciljeve.
- Jedan od poznatih problema dubokog učenja jest da ono radi na principu tzv. crne kutije, odnosno, ne zna se kako točno algoritmi dolaze do zaključaka i preporuka na temelju kojih se posljedično donose poslovne odluke, što znači da se ne možemo slijepo osloniti na njih. To znači da, iako su tehnike dubokog učenja po rezultatima superiorne mnogim drugim tehnikama, mnogi biznisi ih nisu spremni upotrijebiti ako nije moguće objasniti krajnji rezultat - rekla je Hajdi Ćenan.

To je, dodaje, dovelo do toga da sve više tvrtki, osim točnosti modela, traži i objašnjivost dubokog učenja.
Davor Runje pojašnjava kako su trenutna rješenja koja to pokušavaju osigurati izuzetno kompleksna te zbog toga neefikasna.
- Našim fokusom na poslovne podatke došli smo do niza uvida i inovacija koje nisu primjenjive u do sada najrazvijenijim domenama dubokog učenja - vizualnim i jezičnim - ali su se pokazali ključnima u poslovnim primjenama. Poslovni modeli bitno su različiti od vizualnih i jezičnih, prije svega zbog dinamike kojom se mijenja situacija na tržištu te sve naše inovacije uzimaju vrijeme kao dimenziju koja zahtijeva posebnu brigu i specijalizirana rješenja – ističe Runje.

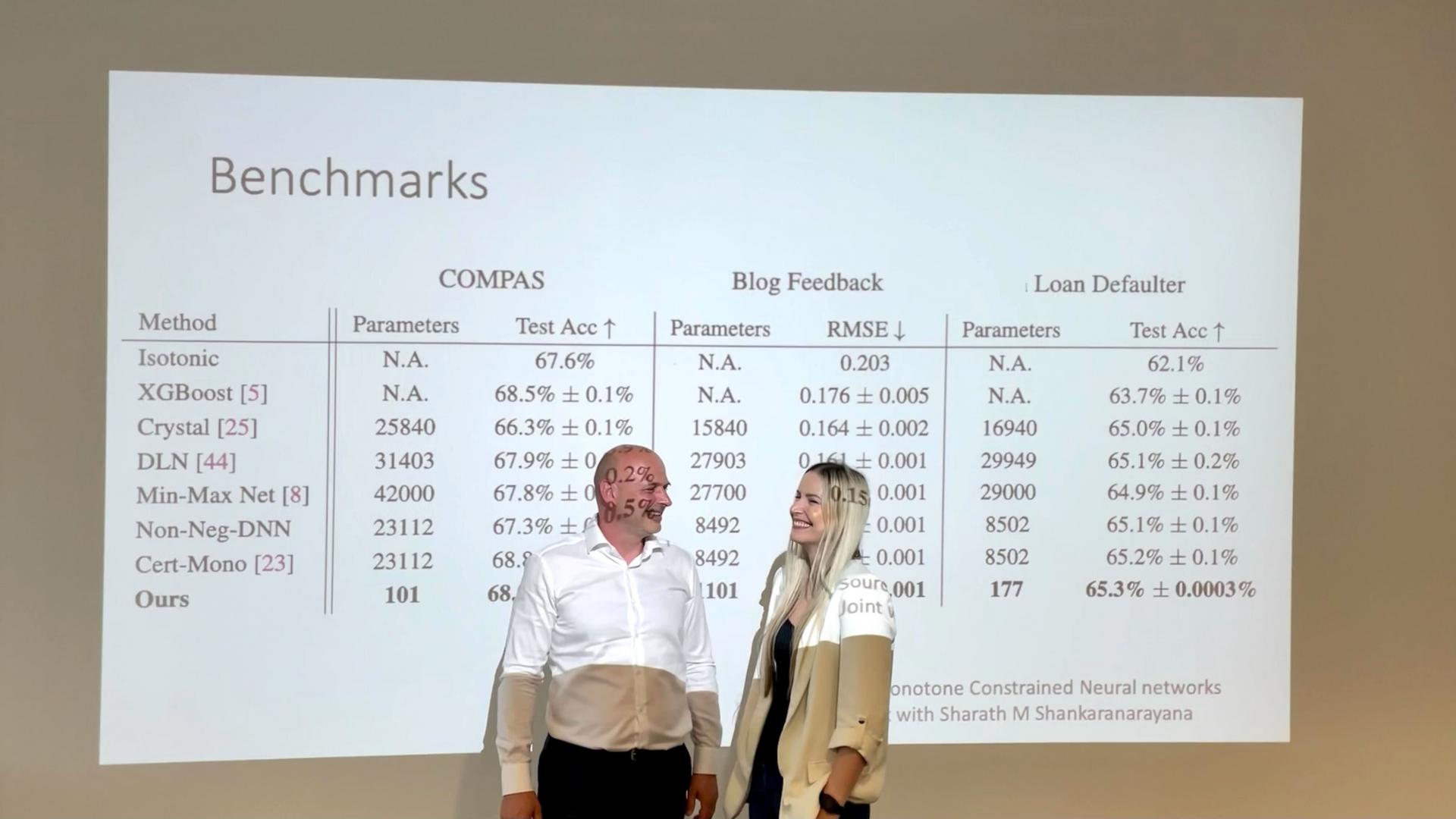
Također kazuju kako je jedna od posljedica tih inovacija i iznimno energetski efikasan sustav za automatsku izradu prediktivnih modela. Ne samo da su svojim pristupom pronašli način kako unijeti objašnjivost u duboko učenje i osigurati konzistentnost rezultata bez gubitka efikasnosti i točnosti koje donosi korištenje neuronskih mreža, već to uspijevaju realizirati i korištenjem barem 100 puta manje parametara, što znatno utječe na ukupno korištenje računalnih resursa potrebnih za treniranje podataka i izradu predikcija.
- Najveći uspjesi tehnika dubokog učenja postignuti su u područjima obrade slike i teksta, a za izradu samo jednog takvog vrhunskog modela potrebne su tisuće ili čak deseci tisuća dolara za električnu energiju potrošenu za njihovu izradu. Međutim, kada govorimo o (mnogobrojnim) modelima koji se koriste u poslovnoj domeni, jasno je da je malo tvrtki koje bi si tako nešto mogle priuštiti - kazala je Hajdi Ćenan.
Davor Runje dodaje kako je njihov cilj da postignu gotovo identične rezultate kao i ovi skupi modeli, ali za puno manje novaca kako bi njihovo rješenje bilo dostupno svima, od najmanjeg web shopa do najvećih financijskih ustanova.
-Tako smo na jednostavan način uspjeli riješiti i problem koji u literaturi postoji već 30 godina, a koji osigurava monotonost modela dubokog učenja (kada, ovisno o ulaznom parametru, funkcija može ili samo rasti ili samo padati) i time pridonosi njihovoj objašnjivosti - ističe Runje.
Pojašnjavaju nadalje kako time izravno utječu i na stranu dubokog učenja o kojoj se još previše ne govori, a to je utjecaj na okoliš jer moderni AI modeli troše iznimno veliku količinu energije. Računalni resursi potrebni za izradu najboljih modela eksponencijalno se povećavaju udvostručujući se svako 3,4 mjeseca, odnosno, drugim riječima, u periodu od 2012. do 2018. godine povećali su se čak 300 tisuća puta. Izračunali su i koliko bi tvrtka s milijun krajnjih korisnika za koje želi raditi prediktivnu analitiku smanjila emisiju CO2 kada bi koristila njihove tehnike umjesto trenutnih standarda: čak pola metričke tone godišnje!
Osnivači ovog startupa kazuju i kako airt gradi platformu za izradu prediktivnih modela na strukturiranim podacima kakvi, primjerice, postoje u bankama ili kod pružatelja komunikacijskih usluga, i za obradu tih podataka interno su razvili vlastite tehnike dubokog učenja inspirirane metodologijama koja se koriste u obradi jezika (NLP/Natural Language Processing). Iskustvo rada na konkretnim problemima iz financijskog sektora upotrijebili su kako bi izgradili potpuno automatiziranu platformu za pripremu transakcijskih podataka te automatiziranu izgradnju modela za konkretne poslovne probleme.
Tu svoju platformu sada pripremaju i kao open-source rješenje s dvostrukom licencom.
- Open-source pristup vidimo kao način da naše rješenje bude što dostupnije svima, da ga svi mogu isprobati i istestirati na što jednostavniji način i brzo se uvjeriti u efikasnost naših inovativnih modela. Ubrzo ćemo objaviti open-source verziju naših neuronskih mreža, a zatim i platforme kao takve – zaključuje Davor Runje.